本文从应用开发者角度给予一些IO知识介绍,因篇幅问题,很多内容只做了粗略介绍,因IO涉及知识体系众多,读者若感兴趣可以对某个方向进行深入研究,本文不做赘述。若本文有错误之处,各位可以在下面评论处指出,感谢大家阅读本文。
性能优化容易忽视的点:IO
在Android主线程进行IO易导致主线程耗时过长,从而引起应用卡顿, 这是Android开发者的共识,Android官方也对此没有强制限制, 全凭开发者“自觉”。而在平时的ANR以及卡顿分析中,发现很多耗时都因为主线程的IO,因此补齐IO知识储备,工程师们才能很好的进行对应问题的优化工作。
从其他角度来看,即使非Android开发者,也需要注意IO带来的影响。因为IO带来的耗时常是不受重视的,其也往往容易成为拖累整个程序运行性能的瓶颈,因此我们在设计程序架构的时候,需要更多考虑IO带来的影响。(Android 在主线程Inflate布局这种设计,本就是不是一个优秀的架构设计,为此后面Google也一直在进行尝试取消掉xml布局这个事情,如推出了Jetpack Compose声明式UI工具包等)
IO背景知识
要想写出高效的IO,需要掌握IO原理,流程。既然如此,让我们看下一次IO都发生了什么?
IO流程
一次write的过程,从应用层出发到达磁盘的写入,需要经历以下的流程。(以下是一次IO的基本流程图)
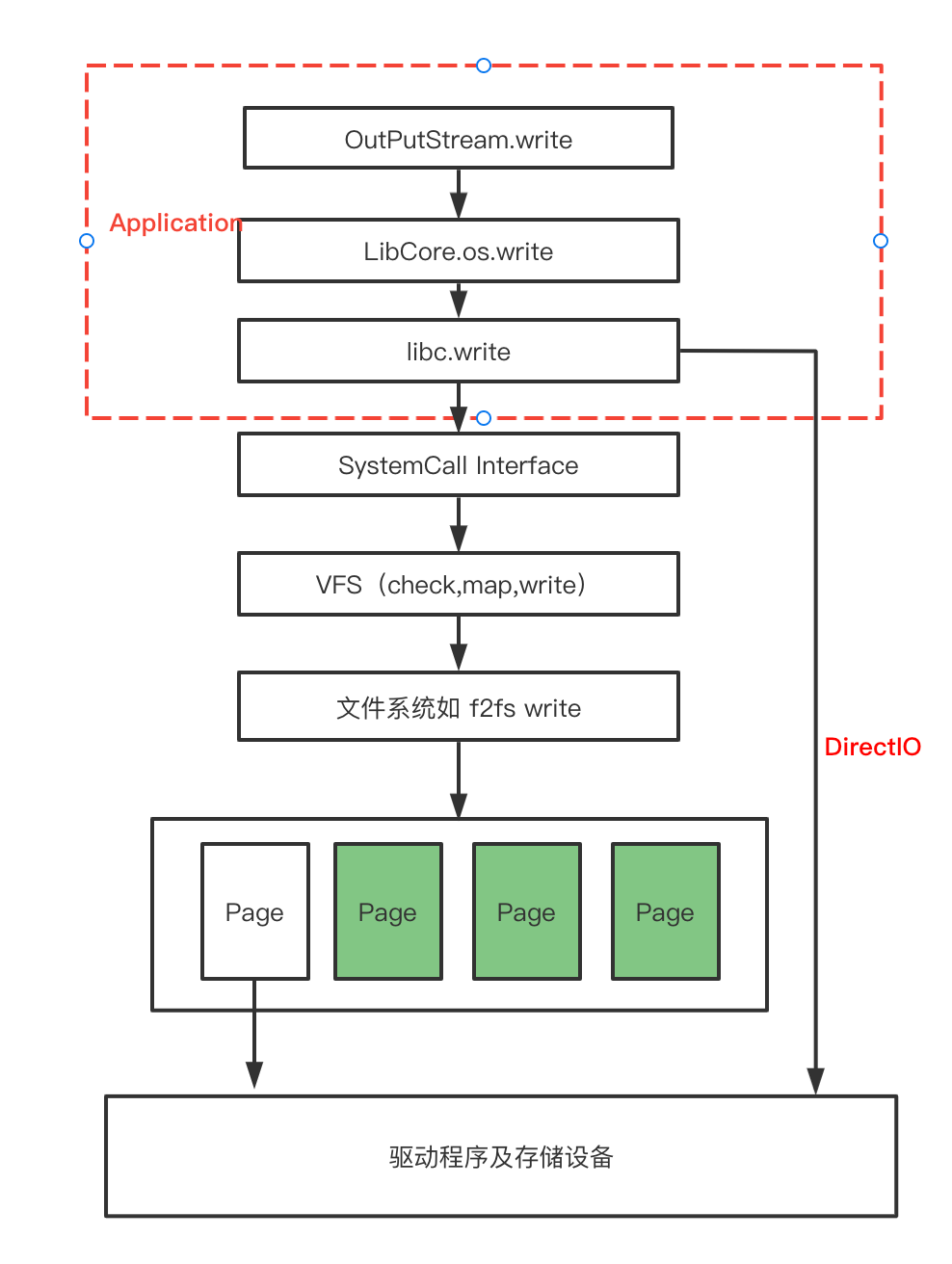
Java的IO,从IO库出发,会直接调用到 LibCore.os 的write 方法。(LibCore.os 是Java的操作系统代理,里面定义了基本的系统调用方法,由该类可以调用到具体系统的系统调用。让程序员不需要关心不同的系统上系统调用不同的实现)
在应用程序走到libc的write后,发生了系统调用(System Call),数据从应用程序空间copy至系统内核空间。随后进行系统层的VFS映射检查等操作。
当然,上层应用程序,可以通过directIO,直接访问底层硬件存储,而不需要进行系统调用的一次copy,如:数据库有着自己的缓存逻辑,不需要page cache,数据库有其自己的缓存算法与事务操作,另外某些业务有自己实现的文件系统等,其自己需要一块存储区域自己进行管理,运行自己的文件系统。
VFS(Virtual Filesystem)
Android 基于 Linux 实现。一切皆文件是Linux的一大特征,其为实现一切皆文件且能支持多种文件系统的特性,添加了 VFS 层,通过 VFS 层进行访问控制与数据结构抽象,来将文件操作请求转发给具体的文件系统。
Linux源码master分支目前支持的VFS:https://github.com/torvalds/linux/tree/master/fs
在开发者的日常工作中,写入文件到不同的文件夹从开发者角度并没有感觉到什么不同,通常都会封装一个方法,不同的文件夹只是不同的路径的区别。而事实上,实际操作的时候,有可能是不同的文件系统。如:应用内部存储(data/data) 与 外部存储(external对应的文件夹)一般情况都不是同一种文件系统。通过系统层将不同的底层硬件的差异进行差分处理,然后封装统一的接口提供给应用层开发调用,这就是VFS的意义。
/proc 文件夹就是典型的vfs的使用场景。 当我们cat 这些文件的时候,可以看到里面存在很多数据,但实际上这些文件都不存在,存储占用大小为0

具体文件系统
这里指的就是不同的具体文件系统实现,每个文件系统都有其自己的特性,常见的文件系统有:EXT2,EXT4,F2FS,NTFS等。这一层关注的是具体文件系统优化,我们不做赘述。
在经过系统的VFS映射后,我们的write数据会到达具体的文件系统层。但即使这样,我们也不会直接写到磁盘中。因为有page的存在,我们正常使用的都是缓冲式IO(标准IO)
如何查看我们目录对应的具体文件系统挂载?
使用mount命令, adb shell mount 之后查看自己想知道的目录的对应挂载文件系统即可。
Page Cache
PageCache是内存中的一块区域,这样做的好处是,在写入的时候不直接写入硬盘,而是写入内存pages中,稍后由系统自主控制写入硬盘。(由多个条件控制何时写入,如空闲内存低于某个阈值,pages驻留时间超时等)
在读取数据时候也一样,首先到page cache中查找(page cache中的每一个数据块都设置了文件以及偏移信息),如果未命中,则启动磁盘I/O,将磁盘文件中的数据块加载到page cache中的一个空闲块。之后再copy到用户缓冲区中。
PageCache的出现,可以降低磁盘 I/O 的次数,在频繁读写的场景中,会带来较大的性能提升。
这种Page cache的缓存IO也有其缺点:数据在传输过程中需要进行多次copy,带来了较大的额外CPU和内存开销。
Disk
磁盘指具体硬件设备。系统通过驱动程序操作磁盘。磁盘一般分为:机械硬盘 与 固态硬盘.我们的业务的磁盘性能一般由硬件性能决定(磁盘碎片也会对性能产生一定的影响)

闪存介绍(Flash)
闪存属于Disk的一种,但闪存的类型分为很多种,从结构上主要能够分为AND、NAND、NOR、DiNOR等一些类型,在这之中,NAND和NOR是我们目前为止在手机中最为常见的使用的类型 (在这之前存储用 EEPROM ,单片机书上提过这个东西, flash属于这广义的EEPROM一种)
NOR Flash
NOR Flash 最大的特点是可以直接在芯片内运行代码,这样不需要把代码读取到RAM中在运行。也就是它既能像ram一样工作,又能像flash一下擦写,这一特性使其拥有很多应用场景
苹果的AirPods就是使用了Nor FLash,该器件由国内的兆易创新供应。
Intel于1988年首先开发出NOR flash技术。NOR Flash擦写速度慢,成本高等特性,NOR Flash 主要应用于小容量、内容更新少的场景,例如 PC 主板 BIOS、路由器系统存储等。
但对于大存储容量,以及考虑成本的情况下NAND flash往往是更优的方案。
NAND Flash
相比于 NOR Flash,NAND Flash 写入性能好,大容量下成本低。目前,绝大部分手机和平板等移动设备中所使用的 eMMC 内部的 Flash Memory 都属于 NAND Flash

什么是EMMC和UFS
EMMC相当于一个Nand Flash加上一个控制器。即:这个flash的操作由卖Flash的上游厂商全部负责,(有点像总成的意思),负责使用的厂商只需要关心其业务就行。同样,后续的UFS2.1 UFS3.0 UFS3.1 也都是这么个概念。随着硬件与软件的进步,我们的存储速度越来越快。
EMMC与UFS相比的显著差距是,同一时刻只能进行读取或者写入一种状态,而UFS可以进行全双工工作模式,能够同时进行读写,因此速度也更优。
Flash的读写
闪存基本构成是由:页page(4K)→块block(通常64个page组成一个block,有的是128个)。闪存还有个特点,就是无法覆盖写,已经有数据的地方写入必须先擦除,擦除完再次写入。因此一开始在使用的过程中,都会优先写入没有数据的地方。等用了过了一阵子,就会发现手机变卡了。这里面有一部分就是这个擦除导致。
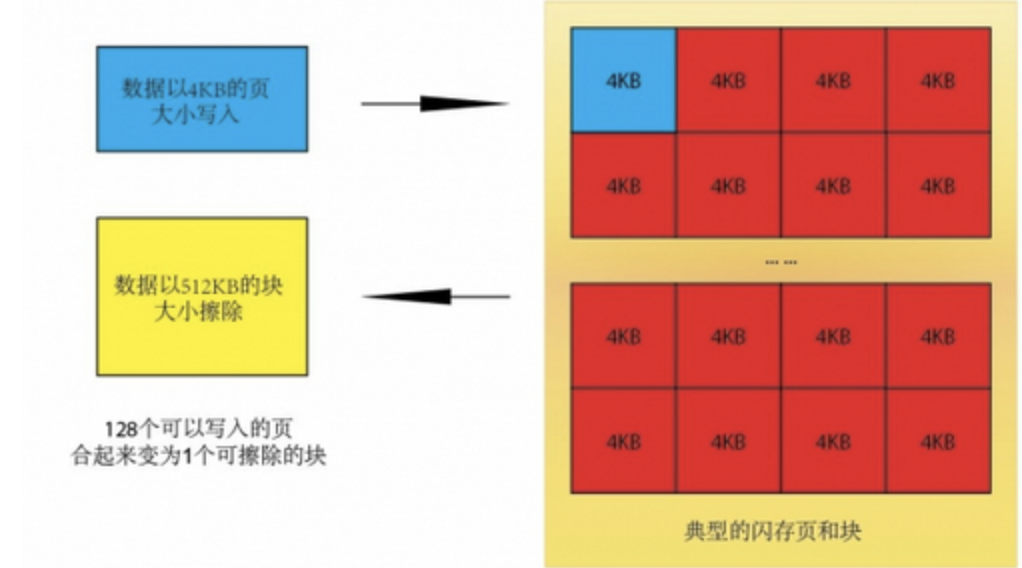
擦除流程有一个致命的问题,NAND Flash可以写page,但是无法擦除page,需要直接擦除block。如果系统中没有空闲的page写了,必须整理出一个空间进行写入,那么这次写入需要消耗的时间远超出想象。也就是:为什么手机只剩1G存储空间了,就会特别卡
这便是写入放大,一次写入的实际写入数量超出本次写入数据的很多倍。
从本质上来讲,我们很难解决写入放大现象,比较好的一个方案是整理磁盘碎片,比如在用户睡眠+充电的情况下,进行整理。而作为开发者,我们只能接受存在这种情况的可能,也就是难以避免IO的异常耗时,但这必须引起我们的重视,主线程尽量不要IO。
一个小小的IO写入,并不一定像你在测试机上看到的或者测试到的那么流畅。有些用户用着你写的程序可能非常容易出现ANR。IO方案选择
此博客的主要篇幅为IO背景知识,因NIO的知识体系过于庞大,其分为服务端的应用与普通IO/系统调用/内存映射等相关知识,此处只做粗略介绍。
BIO (Blocking I/O)
常规的libc API,常规Java IO用法,都是BIO,既阻塞式IO。
(注:此处存在一处争议,如《Think in Java》中提到提到Java1.4之后 FileInputStream默认使用NIO来实现,但是Android中替换了该实现,改回了IoBridge, 此处我们暂将FileInputStream归类为BIO)
阻塞式IO的特点是:当进行IO操作时,会因为等待相关资源而使当前线程进阻塞状态,需要等到IO资源准备完毕,即数据写入完毕/读取完毕,线程则进入唤醒状态。
设想一下,如果有50个线程进行并发读取,其带来的阻塞,唤醒开销会非常大。而在服务器的socket开发中,这种模式远远无法满足需求,因此BIO有其局限性。
NIO(New I/O 或 Non-blocking I/O)
NIO个人更倾向于称之为:Non-blocking I/O,非阻塞式IO。相较于BIO,其采用高性能的非阻塞方式避免出现同步IO带来的低效率问题。这使得NIO在服务端开发中大展身手。
其主要类在:java.nio包,引入了以下几种概念:
Channel
Selector
Buffer
如:Buffer下的allocateDirect(int capacity) 方法。其底层实现为unsafe与runtime进行native的内存操作,能提高数据操作的速度,当另一个方面,分配直接缓冲区的系统开销很大,因此只有在缓冲区较大且长期存在,或者经常重用的情况下,才使用这种缓冲区。
源码见: http://androidxref.com/9.0.0_r3/xref/libcore/ojluni/src/main/java/java/nio/DirectByteBuffer.java
59 // Reference to original DirectByteBuffer that held this MemoryRef. The field is set
60 // only for the MemoryRef created through JNI NewDirectByteBuffer(void*, long) function.
61 // This allows users of JNI NewDirectByteBuffer to create a PhantomReference on the
62 // DirectByteBuffer instance that will only be put in the associated ReferenceQueue when
63 // the underlying memory is not referenced by any DirectByteBuffer instance. The
64 // MemoryRef can outlive the original DirectByteBuffer instance if, for example, slice()
65 // or asReadOnlyBuffer() are called and all strong references to the original DirectByteBuffer
66 // are discarded.
67 final Object originalBufferObject;
68
69 MemoryRef(int capacity) {
70 VMRuntime runtime = VMRuntime.getRuntime();
71 buffer = (byte[]) runtime.newNonMovableArray(byte.class, capacity + 7);
72 allocatedAddress = runtime.addressOf(buffer);
73 // Offset is set to handle the alignment: http://b/16449607
74 offset = (int) (((allocatedAddress + 7) & ~(long) 7) - allocatedAddress);
75 isAccessible = true;
76 isFreed = false;
77 originalBufferObject = null;
78 }
236 /**
237 * Allocates a new direct byte buffer.
238 *
239 * <p> The new buffer's position will be zero, its limit will be its
240 * capacity, its mark will be undefined, and each of its elements will be
241 * initialized to zero. Whether or not it has a
242 * {@link #hasArray backing array} is unspecified.
243 *
244 * @param capacity
245 * The new buffer's capacity, in bytes
246 *
247 * @return The new byte buffer
248 *
249 * @throws IllegalArgumentException
250 * If the <tt>capacity</tt> is a negative integer
251 */
252 public static ByteBuffer allocateDirect(int capacity) {
253 if (capacity < 0) {
254 throw new IllegalArgumentException("capacity < 0: " + capacity);
255 }
256
257 DirectByteBuffer.MemoryRef memoryRef = new DirectByteBuffer.MemoryRef(capacity);
258 return new DirectByteBuffer(capacity, memoryRef);
259 }
260
又比如使用MappedByteBuffer进行内存映射提高文件处理速度:
https://www.cnblogs.com/qing-gee/p/11352668.html
这样的例子还有很多,如使用NIO减少系统调用copy次数等等,我们需要了解NIO的各类的使用,才能写出更加高效IO的代码。
具体NIO的使用方法,在阅读nio源码的同时,可以参考这本书:《NIO与Socket编程技术指南》- 高洪岩
了解Android文件系统
Android的文件系统,由于各目录的需求不一样,如应用的私有数据需要绝对安全不可给除应用自身的任何应用访问,又如部分目录需要作为公共目录供各个应用读写。因此在实现上,也使用了不同的文件系统方案进行不同的权限管理。
因为如果让我实现这些功能,势必要在filesystem进行插桩,每个接口进行插桩一是改了原文件系统的代码,二是需要熟读之前的文件系统并且进行每个接口的测试与判断,不如索性直接新写一个VFS,新的VFS的底层实现用原来的filesystem。
Android系统从应用层角度来看分为:
- 内部存储空间,即
data/data目录下的应用文件夹 - 外部存储空间,即
sdcard或者称之为/storage/emulated/{userID}下的文件夹 (根目录下的sdcard只是一个软链接)
下面我们从这两个分类分析下这两个存储空间的区别。
内部存储空间(data/data)沙盒原理
内部存储空间的设计初衷是严控沙盒机制,即:每个应用都只能访问自己的文件夹,且该文件夹会随着应用的卸载而删除。
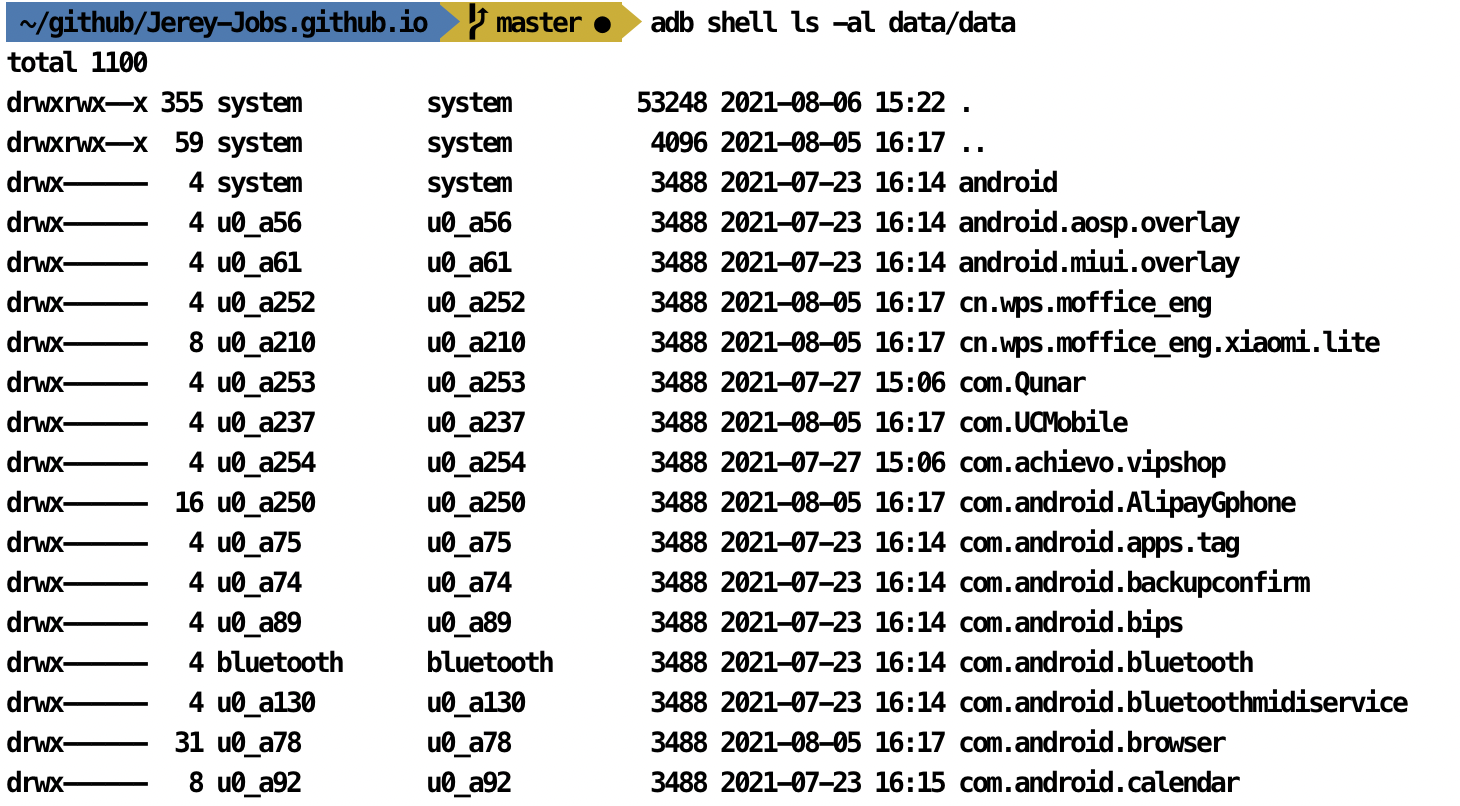
那么从设计角度来说,data分区下, 挂载能够管控权限的文件系统即可, 如:使得应用与应用间不能互相访问文件,即实现data/data下的沙盒机制, 此时可以使用owner与group均为应用自己即可. 这样应用间无法访问文件. 大家可以找一个root过的手机;
adb shell ls -al data/data
可以看到如下的文件信息,文件夹权限通过uid来管控,每个文件夹的权限都是 700 这也就是Android 系统上应用间数据无法共享访问的原理。除了root用户,其他用户都无权限访问(甚至部分root用户因为SE权限的设定,也无法访问该目录)
如果希望其他第三方应用能够访问应用内数据,可以使用FileProvider 或者索性将数据写入到sdcard中。
外部存储空间下的权限管理
sdcard分区下, 也需要一个管理应用访问权限的系统,在Android R之前, 用的sdcardfs, 在这之后,用的是f2fs+Fuse.
让我们在android 11的手机上敲下: adb shell mount 看下各个目录的挂载情况。
/dev/fuse on /storage/emulated type fuse (rw,lazytime,nosuid,nodev,noexec,noatime,user_id=0,group_id=0,allow_other)
/data/media on /storage/emulated/0/Android/data type sdcardfs (rw,nosuid,nodev,noexec,noatime,fsuid=1023,fsgid=1023,gid=1015,multiuser,mask=6,derive_gid,default_normal,unshared_obb)
我们可以得到结论:
/storage/emulated/0/Android/data 也就是平时大家用的 ‘getExternalFilesDir’ 在Android R上其文件系统为:f2fs (这个目录在Android Q上是 sdcardfs)
如果我们对f2fs与sdcardfs 读写测试,会得到以下结论:f2fs在文件创建效率方面相比于sdcardfs会快的多。因此在Android R上,此区域的IO性能其实是得到了增强的。
sdcard的情况比较特殊,在Android R之前,使用Google的sdcardfs对目录进行权限管理。
注:sdcardfs实现的较为简单,而且有其弊端,在深层次目录的大量文件情况下,IO效率下降非常厉害,直接使用 f2fs 没有这个问题
adb shell ls -al /sdcard/Android/data adb shell ls -al /sdcard/
从上面的分析,可以得出结论是,开发者应用尽量减少IO的使用,或者说:非必要不写IO,能够内存中解决的,在内存中完成即可。如果实在需要IO,我们应尝试以下办法。
选择正确的数据存储目录,避免低效IO
相信看了上面不同路径对应的挂载不同的原理后,我们对存储目录的选择有了更谨慎的判断,写入遵循几个原则就不会出大错:
- 应用尽量不访问外置SDcard,存储到应用私有目录下(避免fuse)
- 目录层级不要过深,十几级的目录层级在部分文件系统上会出现性能严重下降的情况
- 单个文件夹数量不宜过多,如:在某个文件夹下存放了10w个缓存文件,不同的文件系统表现会差很多, 单个目录下过多的子文件会导致文件系统的索引效率下降。
也有一些文件系统限制了单个文件夹文件数,如:FAT32限制单个文件夹下文件数量不能超过65534个,EXT3最大是32000个。
(这点IOS系统做的很棒,拍摄的照片都存在
DCIM里的Apple**目录下,每个目录文件都在 百的数量级,反观Android,都存在DCIM/Camera中,那么512G的手机拍了200个G的照片情况,这样的存储方式很明显不是一个较优解) - 控制合理的文件名长度,建议不超过32字节。这是由系统Linux系统定义的 DNAME_INLINE_LEN 决定的,当文件名的长度大于这个值,dentry会开辟新空间存放该文件名,而小于该空间则直接放在文件系统的dentry的一个数组中。而开辟空间会带来额外的开销与内存碎片。
选择正确的IO方案,达到高效IO
本文不给出具体选择方案。比如移动一个文件的IO方案,copy一个文件的方案,大量数据文件夹的遍历方案,文件读取方案等等,都希望工程师们有自己的判断,而不是依赖了此篇文章。(抑或受此篇文章影响选错了方案),因此本文只提供了多种可能性,不帮读者进行选择。
只需要知道,在选择正确的IO方案前,我们需要有足够的NIO,BIO知识储备,操作系统知识储备。
减少Android主线程IO操作
持久化 key-value
在开发中,我们经常需要本地存储下一些持久化的记录,同时这些记录可能需要不断的更新到本地。 甚至有些情况,我们需要多进程访问这一个值。
在服务端的发展史上也经常有这个需求,因此诞生了Redis等框架。
若不需要多进程访问,常用的一个方案是使用 SharedPreference使用apply替代commit操作即可避免主线程IO带来的耗时。但是在多线程的使用中,会出现“脏读”,“幻读”的情况。
解决这个问题的替代方案,可以使用本地数据库 or ContentProvider 进行多进程KV管理。
这里推荐使用基于内存映射+文件锁方案的MMKV,因为已经在微信上稳定运行好几年,有其稳定性保证: MMKV - https://zhuanlan.zhihu.com/p/47420264
加载布局文件的IO (Inflate耗时)
为了解决/优化这个问题带来的体验。Android推出了RecyclerView 等组件,来解决列表华滑动时因重复inflate带来的主线程IO引起的卡顿问题,但有些场景需要动态的添加新view,此时inflate的耗时不可避免。
可以使用AsyncLayoutInflater + cache 的方案优化这个问题。
加载本地图片的IO耗时
本地图片加载也可以使用以下几种方案:
AyncImageLoader
Glide
Bitmap缓存
为了解决IO的耗时,大家还做了哪些?
zipAlignEnabled
zipAlign 是 Android官方提供的一个优化方案,最简单的使用方式是在 build.gradle 的 buildTypes 中添加 zipAlignEnabled true 配置
zipalign优化的最根本目的是帮助操作系统更高效率的根据请求索引资源,将resource-handling code统一将Data structure alignment(数据结构对齐标准:DSA)限定为4-byte boundaries。
优化PageCache的命中率,提高app的启动速度
- 支付宝:通过安装包重排布优化 Android 端启动性能
通过安装包重排布优化 Android 端启动性能 https://developer.aliyun.com/article/673875
ReDex重布局,
也是优化 Class 字节码布局。Facebook 通过线上及线下测试,启动速度提升 20% 以上,Dex 大小减小 25%,对于内存较小的机型启动速度的优化效果尤其明显。
https://engineering.fb.com/2015/10/01/android/optimizing-android-bytecode-with-redex/
总结寄语
因篇幅问题,本文涉及到的很多领域知识只进行了笼统的介绍。本文面向主要读者为:Android应用开发者。
在平时工作中,很多时候开发者因为种种原因可能会忽视一个调用的优化,虽然只是一些小小的优化,有可能只是“去掉一次copy”,“少输出了一行log”,“少了一次系统调用”,导致程序运行的比本该运行的慢了一点。但千里之堤毁于蚁穴,若程序中处处都存在这些细小的问题,整个程序的综合体验又如何能达到极致?
上述并不是表达我对当下的不满,有时候,有可能因为需求的紧急,不得不写出更方便的但效率相对较低/不稳定的代码。但开发者应仍有追求极致的信念,使得整个生态变得更佳。
– 夏敏,写于2021年末,工作于小米集团南京分公司
个人邮箱:jerey_jobs@qq.com
内推邮箱:xiamin@xiaomi.com
– 感谢我的爱人李白云女士对我一直以来的支持。
小米集团招聘内推:

部分来源:
《Linux内核源代码导读》-陈香兰
《Think in Java》 - Bruce Eckel
《Java高并发核心编程》- 尼恩